Binary imbalanced data classification based on diversity oversampling by generative models
Abstract
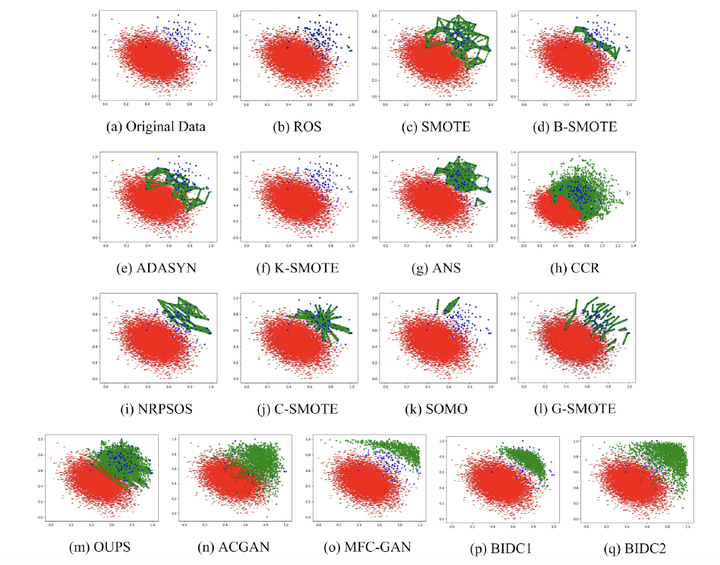
In many practical applications, the data are class imbalanced. Accordingly, it is very meaningful and valuable to investigate the classification of imbalanced data. In the framework of binary imbalanced data classification, the synthetic minority oversampling technique (SMOTE) is the best-known oversampling method. However, for each positive sample, SMOTE generates only k synthetic samples on the lines between the positive sample and its k-nearest neighbors, resulting in three drawbacks: (1) SMOTE cannot effectively extend the training field of positive samples; (2) the generated positive samples lack diversity; (3) SMOTE does not accurately approximate the probability distribution of the positive samples. Therefore, two binary imbalanced data classification methods named BIDC1 and BIDC2 based on diversity oversampling by generative models are proposed. The BIDC1 and BIDC2 conduct diversity oversampling using extreme learning machine autoencoder and generative adversarial network, respectively. Extensive experiments on 26 data sets are conducted to compare the two methods with 14 state-of-the-art methods using five metrics: F-measure, G-means, AUC-area, MMD-score, and Silhouette-score. The experimental results demonstrate that the two methods outperform the other 14 methods.
Abdullah Mamun
Graduate Research Associate
Currently I am working on building and optimizing deep learning models for time-series data.