A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions
Abstract
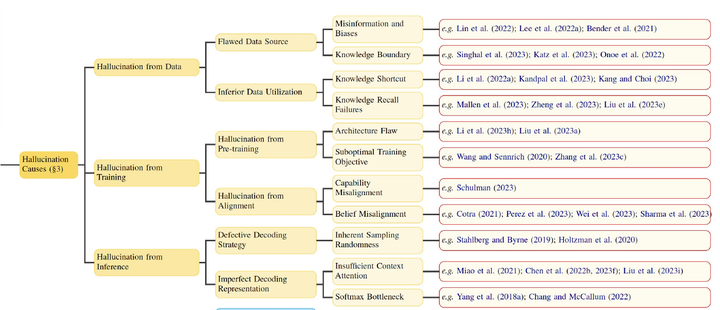
The emergence of large language models (LLMs) has marked a significant breakthrough in natural language processing (NLP), fueling a paradigm shift in information acquisition. Nevertheless, LLMs are prone to hallucination, generating plausible yet nonfactual content. This phenomenon raises significant concerns over the reliability of LLMs in real-world information retrieval (IR) systems and has attracted intensive research to detect and mitigate such hallucinations. Given the open-ended general-purpose attributes inherent to LLMs, LLM hallucinations present distinct challenges that diverge from prior task-specific models. This divergence highlights the urgency for a nuanced understanding and comprehensive overview of recent advances in LLM hallucinations. In this survey, we begin with an innovative taxonomy of hallucination in the era of LLM and then delve into the factors contributing to hallucinations. Subsequently, we present a thorough overview of hallucination detection methods and benchmarks. Our discussion then transfers to representative methodologies for mitigating LLM hallucinations. Additionally, we delve into the current limitations faced by retrieval-augmented LLMs in combating hallucinations, offering insights for developing more robust IR systems. Finally, we highlight the promising research directions on LLM hallucinations, including hallucination in large vision-language models and understanding of knowledge boundaries in LLM hallucinations.
Abdullah Mamun
Graduate Research Associate
Currently I am working on building and optimizing deep learning models for time-series data.